Setup Ollama on RaspberryPi
Introduction

Introduction
In the fast-growing area of artificial intelligence, edge computing presents an opportunity to decentralize capabilities traditionally reserved for powerful, centralized servers. This lab explores the practical integration of small versions of traditional large language models (LLMs) into a Raspberry Pi 5, transforming this edge device into an AI hub capable of real-time, on-site data processing.
As large language models grow in size and complexity, Small Language Models (SLMs) offer a compelling alternative for edge devices, striking a balance between performance and resource efficiency. By running these models directly on Raspberry Pi, we can create responsive, privacy-preserving applications that operate even in environments with limited or no internet connectivity.
This chapter will guide you through setting up, optimizing, and leveraging SLMs on Raspberry Pi. We will explore the installation and utilization of Ollama. This open-source framework allows us to run LLMs locally on our machines (our desktops or edge devices such as the Raspberry Pis or NVidia Jetsons). Ollama is designed to be efficient, scalable, and easy to use, making it a good option for deploying AI models such as Microsoft Phi, Google Gemma, Meta Llama, and LLaVa (Multimodal). We will integrate some of those models into projects using Python's ecosystem, exploring their potential in real-world scenarios (or at least point in this direction).

Ollama

Ollama is an open-source framework that allows us to run language models (LMs), large or small, locally on our machines. Here are some critical points about Ollama:
-
Local Model Execution: Ollama enables running LMs on personal computers or edge devices such as the Raspi-5, eliminating the need for cloud-based API calls.
-
Ease of Use: It provides a simple command-line interface for downloading, running, and managing different language models.
-
Model Variety: Ollama supports various LLMs, including Phi, Gemma, Llama, Mistral, and other open-source models.
-
Customization: Users can create and share custom models tailored to specific needs or domains.
-
Lightweight: Designed to be efficient and run on consumer-grade hardware.
-
API Integration: Offers an API that allows integration with other applications and services.
-
Privacy-Focused: By running models locally, it addresses privacy concerns associated with sending data to external servers.
-
Cross-Platform: Available for macOS, Windows, and Linux systems (our case, here).
-
Active Development: Regularly updated with new features and model support.
-
Community-Driven: Benefits from community contributions and model sharing.
To learn more about what Ollama is and how it works under the hood, you should see this short video from Matt Williams, one of the founders of Ollama:
Matt has an entirely free course about Ollama that we recommend
Installing Ollama
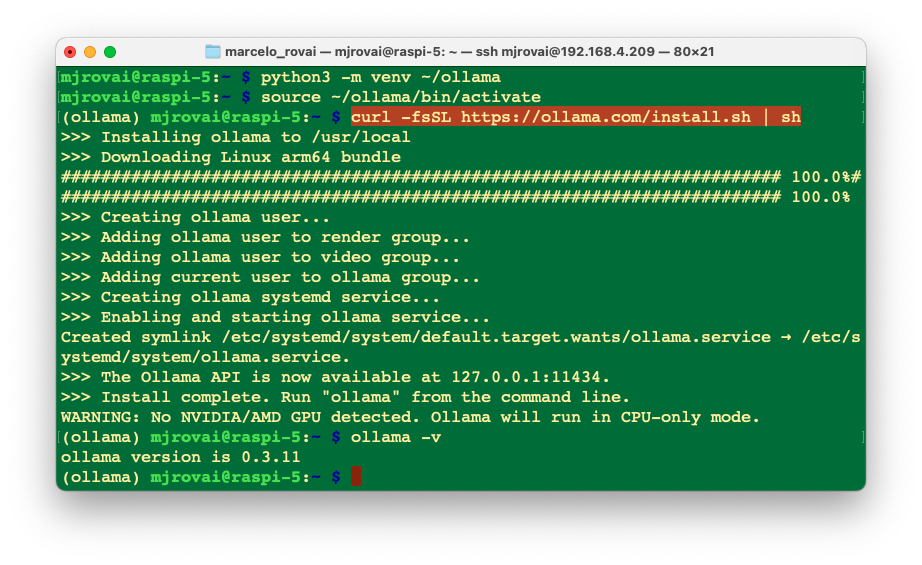
Let's set up and activate a Virtual Environment for working with Ollama:
python3 -m venv ~/ollama
source ~/ollama/bin/activate
And run the command to install Ollama:
curl -fsSL https://ollama.com/install.sh | sh
As a result, an API will run in the background on 127.0.0.1:11434. From now on, we can run Ollama via the terminal. For starting, let's verify the Ollama version, which will also tell us that it is correctly installed:
ollama -v
On the Ollama Library page, we can find the models Ollama supports. For example, by filtering by Most popular, we can see Meta Llama, Google Gemma, Microsoft Phi, LLaVa, etc.