Ollama Python Library
Introduction
So far, we have explored SLMs' chat capability using the command line on a terminal. However, we want to integrate those models into our projects, so Python seems to be the right path. The good news is that Ollama has such a library.
The Ollama Python library simplifies interaction with advanced LLM models, enabling more sophisticated responses and capabilities, besides providing the easiest way to integrate Python 3.8+ projects with Ollama.
For a better understanding of how to create apps using Ollama with Python, we can follow Matt Williams's videos, as the one below:
Install Ollama
In the terminal, run the command:
pip install ollama
Install Python IDE
We will need a text editor or an IDE to create a Python script. If you run the Raspberry OS on a desktop, several options, such as Thonny and Geany, have already been installed by default (accessed by [Menu][Programming]). You can download other IDEs, such as Visual Studio Code, from [Menu][Recommended Software]. When the window pops up, go to [Programming], select the option of your choice, and press [Apply].
If you prefer using Jupyter Notebook for development:
pip install jupyter
jupyter notebook --generate-config
To run Jupyter Notebook, run the command (change the IP address for yours):
jupyter notebook --ip=192.168.4.209 --no-browser
On the terminal, you can see the local URL address to open the notebook:
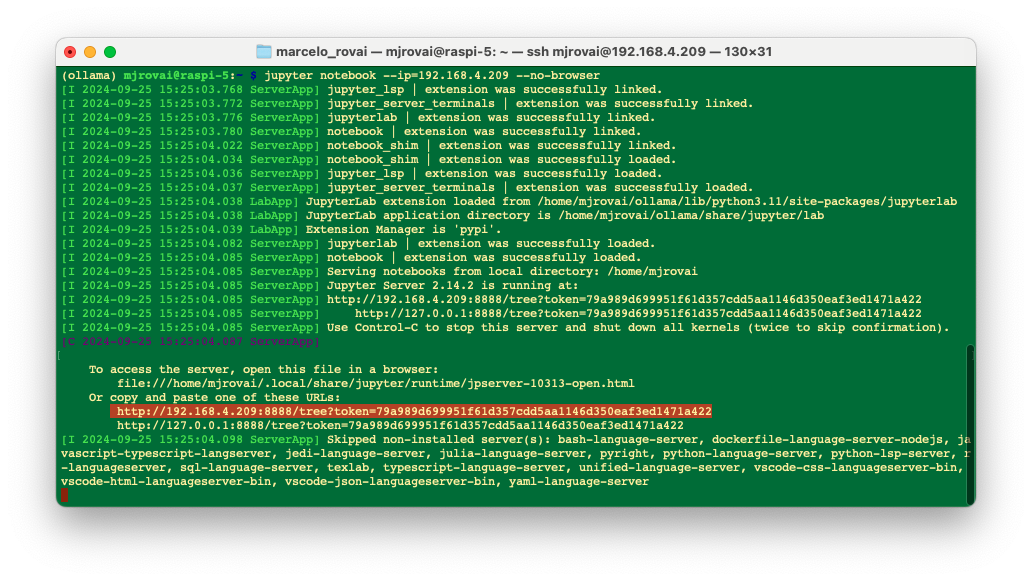
We can access it from another computer by entering the Raspberry Pi's IP address and the provided token in a web browser (we should copy it from the terminal).
In our working directory in the Raspi, we will create a new Python 3 notebook.
Let's enter with a very simple script to verify the installed models:
Check wether Ollama is installed
import ollama
ollama.list()
All the models will be printed as a dictionary, for example:
{'name': 'gemma2:2b',
'model': 'gemma2:2b',
'modified_at': '2024-09-24T19:30:40.053898094+01:00',
'size': 1629518495,
'digest': '8ccf136fdd5298f3ffe2d69862750ea7fb56555fa4d5b18c04e3fa4d82ee09d7',
'details': {'parent_model': '',
'format': 'gguf',
'family': 'gemma2',
'families': ['gemma2'],
'parameter_size': '2.6B',
'quantization_level': 'Q4_0'}}]}
Use Ollama API with Python
Let's repeat one of the questions that we did before, but now using ollama.generate() from Ollama python library. This API will generate a response for the given prompt with the provided model. This is a streaming endpoint, so there will be a series of responses. The final response object will include statistics and additional data from the request.
MODEL = 'gemma2:2b'
PROMPT = 'What is the capital of France?'
res = ollama.generate(model=MODEL, prompt=PROMPT)
print (res)
In case you are running the code as a Python script, you should save it, for example, test_ollama.py. You can use the IDE to run it or do it directly on the terminal. Also, remember that you should always call the model and define it when running a stand-alone script.
python test_ollama.py
As a result, we will have the model response in a JSON format:
{'model': 'gemma2:2b', 'created_at': '2024-09-25T14:43:31.869633807Z',
'response': 'The capital of France is **Paris**. 🇫🇷 \n', 'done': True,
'done_reason': 'stop', 'context': [106, 1645, 108, 1841, 603, 573, 6037, 576,
6081, 235336, 107, 108, 106, 2516, 108, 651, 6037, 576, 6081, 603, 5231, 29437,
168428, 235248, 244304, 241035, 235248, 108], 'total_duration': 24259469458,
'load_duration': 19830013859, 'prompt_eval_count': 16, 'prompt_eval_duration':
1908757000, 'eval_count': 14, 'eval_duration': 2475410000}
As we can see, several pieces of information are generated, such as:
-
response: the main output text generated by the model in response to our prompt.
The capital of France is **Paris**. 🇫🇷
-
context: the token IDs representing the input and context used by the model. Tokens are numerical representations of text used for processing by the language model.
[106, 1645, 108, 1841, 603, 573, 6037, 576, 6081, 235336, 107, 108,106, 2516, 108, 651, 6037, 576, 6081, 603, 5231, 29437, 168428,235248, 244304, 241035, 235248, 108]
The Performance Metrics:
- total_duration: The total time taken for the operation in nanoseconds. In this case, approximately 24.26 seconds.
- load_duration: The time taken to load the model or components in nanoseconds. About 19.38 seconds.
- prompt_eval_duration: The time taken to evaluate the prompt in nanoseconds. Around 1.9.0 seconds.
- eval_count: The number of tokens evaluated during the generation. Here, 14 tokens.
- eval_duration: The time taken for the model to generate the response in nanoseconds. Approximately 2.5 seconds.
But, what we want is the plain 'response' and, perhaps for analysis, the total duration of the inference, so let's change the code to extract it from the dictionary:
print(f"\n{res['response']}")
print(f"\n [INFO] Total Duration: {(res['total_duration']/1e9):.2f} seconds")
Now, we got:
The capital of France is **Paris**. 🇫🇷
[INFO] Total Duration: 24.26 seconds
Use ollama.chat()
Another way to get our response is to use ollama.chat(), which generates the next message in a chat with a provided model. This is a streaming endpoint, so a series of responses will occur. Streaming can be disabled using "stream": false. The final response object will also include statistics and additional data from the request.
PROMPT_1 = 'What is the capital of France?'
response = ollama.chat(model=MODEL, messages=[
{'role': 'user','content': PROMPT_1,},])
resp_1 = response['message']['content']
print(f"\n{resp_1}")
print(f"\n [INFO] Total Duration: {(res['total_duration']/1e9):.2f} seconds")
The answer is the same as before.
An important consideration is that by using ollama.generate(), the response is "clear" from the model's "memory" after the end of inference (only used once), but If we want to keep a conversation, we must use ollama.chat(). Let's see it in action:
PROMPT_1 = 'What is the capital of France?'
response = ollama.chat(model=MODEL, messages=[
{'role': 'user','content': PROMPT_1,},])
resp_1 = response['message']['content']
print(f"\n{resp_1}")
print(f"\n [INFO] Total Duration: {(response['total_duration']/1e9):.2f} seconds")
PROMPT_2 = 'and of Italy?'
response = ollama.chat(model=MODEL, messages=[
{'role': 'user','content': PROMPT_1,},
{'role': 'assistant','content': resp_1,},
{'role': 'user','content': PROMPT_2,},])
resp_2 = response['message']['content']
print(f"\n{resp_2}")
print(f"\n [INFO] Total Duration: {(response['total_duration']/1e9):.2f} seconds")
In the above code, we are running two queries, and the second prompt considers the result of the first one.
Here is how the model responded:
The capital of France is **Paris**. 🇫🇷
[INFO] Total Duration: 2.82 seconds
The capital of Italy is **Rome**. 🇮🇹
[INFO] Total Duration: 4.46 seconds
Getting an image description
In the same way that we have used the LlaVa-PHI-3 model with the command line to analyze an image, the same can be done here with Python. Let's use the same image of Paris, but now with the ollama.generate():
MODEL = 'llava-phi3:3.8b'
PROMPT = "Describe this picture"
with open('image_test_1.jpg', 'rb') as image_file:
img = image_file.read()
response = ollama.generate(
model=MODEL,
prompt=PROMPT,
images= [img]
)
print(f"\n{response['response']}")
print(f"\n [INFO] Total Duration: {(res['total_duration']/1e9):.2f} seconds")
Here is the result:
This image captures the iconic cityscape of Paris, France. The vantage point
is high, providing a panoramic view of the Seine River that meanders through
the heart of the city. Several bridges arch gracefully over the river,
connecting different parts of the city. The Eiffel Tower, an iron lattice
structure with a pointed top and two antennas on its summit, stands tall in the
background, piercing the sky. It is painted in a light gray color, contrasting
against the blue sky speckled with white clouds.
The buildings that line the river are predominantly white or beige, their uniform
color palette broken occasionally by red roofs peeking through. The Seine River
itself appears calm and wide, reflecting the city's architectural beauty in its
surface. On either side of the river, trees add a touch of green to the urban
landscape.
The image is taken from an elevated perspective, looking down on the city. This
viewpoint allows for a comprehensive view of Paris's beautiful architecture and
layout. The relative positions of the buildings, bridges, and other structures
create a harmonious composition that showcases the city's charm.
In summary, this image presents a serene day in Paris, with its architectural
marvels - from the Eiffel Tower to the river-side buildings - all bathed in soft
colors under a clear sky.
[INFO] Total Duration: 256.45 seconds
The model took about 4 minutes (256.45 s) to return with a detailed image description.
In the 10-Ollama_Python_Library notebook, it is possible to find the experiments with the Ollama Python library.
Function Calling
So far, we can see that, with the model's ("response") answer to a variable, we can efficiently work with it, integrating it into real-world projects. However, a big problem is that the model can respond differently to the same prompt. Let's say that what we want, as the model's response in the last examples, is only the name of a given country's capital and its coordinates, nothing more, even with very verbose models such as the Microsoft Phi. We can use the Ollama function's calling to guarantee the same answers, which is perfectly compatible with OpenAI API.
But what exactly is "function calling"?
In modern artificial intelligence, function calling with Large Language Models (LLMs) allows these models to perform actions beyond generating text. By integrating with external functions or APIs, LLMs can access real-time data, automate tasks, and interact with various systems.
For instance, instead of merely responding to a query about the weather, an LLM can call a weather API to fetch the current conditions and provide accurate, up-to-date information. This capability enhances the relevance and accuracy of the model's responses and makes it a powerful tool for driving workflows and automating processes, transforming it into an active participant in real-world applications.
For more details about Function Calling, please see this video made by Marvin Prison:
https://www.youtube.com/embed/eHfMCtlsb1o